在继续往下读之前,先花一点时间问问自己:什么是互联网协议(Internet Protocol,IP)? 除了「它就是设备拿到 IP 地址的方式」之外,你能说清它的用途,以及它到底由哪些部分组成吗?
和很多开发者一样,我对网络栈有一种「够用」的理解:我知道 TCP 提供可靠连接,UDP 用于快速收发消息,而 IP 地址是数据包要去的地方。但当我真正停下来追问一句 「互联网协议到底是什么?」 时,我发现自己卡住了。
对于 IP,我脑子里唯一能浮现的画面就是一个 IP 地址。这就带来了一个根本性的困惑:互联网协议难道只是一套关于地址的标准吗?
答案当然是否定的。在深入研究了它的体系结构之后,我终于建立起了一个能「咔哒」一下想通的心智模型。下面就是我学到的东西。
协议不等于地址
我们先来看看大名鼎鼎的 OSI 模型:
+---------------------+
| Application Layer | (HTTP, FTP, DNS)
+---------------------+
| Transport Layer | (TCP, UDP)
+---------------------+
| Network Layer | (IP)
+---------------------+
| Data Link Layer | (Ethernet, Wi-Fi)
+---------------------+
| Physical Layer | (Cables, Radio Waves)
+---------------------+为什么上面这张图只有 5 层而不是 7 层?
如果你疑惑为什么上图只画了 5 层,而不是通常说的 7 层,可以看看我的频道动态。一句话总结:人们常用一种简化的「互联网协议栈」视角,把 OSI 的会话层(Session)和表示层(Presentation)并入应用层,并把物理层(Physical)和数据链路层(Data Link)合在一起当作「链路」来看待(尽管在严格的 OSI 模型里它们是彼此独立的)。
从这个模型可以很容易地看出 IP 的职责:它工作在网络层(Network Layer),负责把数据包从一台主机跨越不同的网络路由到另一台主机。
我最大的思维障碍,是没能把地址这个名字(IP 地址)和逻辑(IP 协议)区分开。一旦你开始把 IP 理解成一套规则与流程,而不仅仅是一个标签,剩下的一切就都顺理成章了。
互联网是一堆线缆,而 IP 就是在这些线缆之间导航的逻辑。 至于 IP 地址,它是协议的一部分(就像邮政系统里的街道地址),但远不是故事的全部。我曾做过一个关于计算机网络如何为你的数据包选路的小分享,其实 Routing(路由)的逻辑也属于互联网协议的一部分。不仅如此,IP 还定义了数据包是如何组织的(IP 头部)、分片是怎么工作的(注意:过大的数据包可能需要被拆开;在以太网上 MTU 通常是 1500 字节),以及 IP 地址是如何分配的(CIDR、DHCP、SLAAC 等等)。
在我看来,邮局这个类比是网络领域里最好的心智模型之一。当你寄一封信时,邮政系统的运作方式和 IP 的工作方式如出一辙:
- 信封:IP 协议规定了如何把数据打包成数据包,并在头部写上源地址和目的地址。
- 寻址:全国统一的地址系统确保每个地点都有唯一的标识,这正像 IP 地址。
- 选路:邮政系统让信件途经一个个邮局;同样地,IP 让数据包穿过一个个跨网络的路由器。
接下来,我们就带着上面这三个要素,更细致地聊聊路由。
IP 头部
互联网协议只专注于一件事:把一个数据包从计算机 A 送到计算机 B。它完全不关心这个数据包里装的是什么——它不在乎那是一段 4K 视频的片段、一场竞技游戏里的一步操作,还是一个简单的文本文件。
我们先来看看 IPv4 的 IP 头部(图片来源:UC Berkeley CS168):

头部里有这么多字段,但仔细一看,你会发现其中很多都相当有用。比如:
- Version(版本): 表明这是 IPv4 还是 IPv6。
- Source & Destination IP(源 / 目的 IP): 「发件人」和「收件人」地址。我们需要它们来知道把包送往何处,以及把响应送回何处。
- TTL(Time To Live,生存时间): 防止数据包永远地在网络里兜圈子。
- Protocol(协议): 表明负载(payload)是 TCP、UDP、ICMP 还是别的什么。这是为了在目的端对第四层协议进行解复用(demultiplexing),否则负载在收端看来就是一堆乱码。
- Header Checksum(头部校验和): 保证头部数据的完整性。注意: 这个校验和只覆盖头部,不覆盖负载。这正是源于端到端原则(end-to-end principle):负载的完整性由两端的主机负责,而不是中间的路由器。
- Fragmentation Fields(分片字段): 允许把大的数据包拆成更小的分片来传输,并在目的端重新组装。
IPv6 的头部则更简洁、更高效(图片来源:UC Berkeley CS168):

你可以把它看作 IPv4 头部的一次进化,它把端到端原则推得更彻底:
- 移除了头部校验和(完全依赖上层协议来做差错检验)。
- 简化了分片机制(只有源端负责分片,中间的路由器不再分片)。
它还通过 next header(下一个头部)字段保证了可扩展性,让扩展头部得以存在,同时又不让基础头部变得臃肿。
寻址
在谈路由之前,我们必须先问一句:设备一开始究竟是怎么拿到这些地址的?
我们早已告别了 1980 年代那套僵硬的「A/B/C 类」体系,转向了无类别域间路由(CIDR,Classless Inter-Domain Routing)。如果你想了解一下老派的 A/B/C 类体系,可以看看这条频道动态。CIDR 允许我们在任意比特边界上切分 IP 地址空间,从而创建出任意大小的子网,恰到好处地满足需求。
CIDR 记法本身并不复杂;如果你还不熟悉,这里有一个快速回顾:
一个 IP 地址是一个 32 位的数字(IPv4)或 128 位的数字(IPv6)。为简单起见,我们以 IPv4 为例。如果我们想表示一段地址(比如 10.0.0.0 到 10.0.0.255)该怎么办?当然可以写成 10.0.0.*,但这种写法在像 10.0.0.0 到 10.0.0.127 这样的例子上就失效了。于是我们改用 CIDR 记法:用 10.0.0.0/24 表示第一个例子,用 10.0.0.0/25 表示第二个。这里的 /24 或 /25 表示地址中有多少位被固定为网络部分。如果你还是有点晕,我们把它写成二进制看看:
10.0.0.0/24 means:
00001010.00000000.00000000.00000000
|----- 24 bits fixed -----| Hosts |
The first 24 bits define the network, fixed.
The last 8 bits are free for host addresses.
This gives us 2^8 = 256 addresses (10.0.0.0 to 10.0.0.255).
We write `/24` because 24 bits are fixed for the network.
10.0.0.0/25 means:
00001010.00000000.00000000.0|0000000
|------ 25 bits fixed ------| Hosts |
The first 25 bits define the network, fixed.
The last 7 bits are free for host addresses.
This gives us 2^7 = 128 addresses (10.0.0.0 to 10.0.0.127).
We write `/25` because 25 bits are fixed for the network.CIDR 的妙处就在于它的灵活性。你可以在任意比特边界上切分地址空间,创建出恰好所需大小的子网。一个 /30 给你 4 个地址,而一个 /22 给你 个地址。正是这种高效,让互联网得以突破僵硬的 A/B/C 类体系而不断扩展。类似地,对于 IPv6,总位长是 128 位,一个非常常见的局域网子网大小是 /64。
现在来谈个实际问题:到底是谁把地址发给主机的? 这就轮到 DHCP 和 SLAAC 登场了,而它们解决的是略有不同的问题。
DHCP(IPv4)
在 IPv4 中,默认的模型是 DHCP(动态主机配置协议,Dynamic Host Configuration Protocol):由一台服务器在有限的时间内把配置「租借」给客户端。
客户端拿到的通常不止一个 IP:
- IPv4 地址
- 子网掩码(Subnet mask)
- 默认网关(Default gateway)
- DNS 服务器
- 租约时长(Lease time,以及其他选项)
你常常会看到人们用 DORA 来描述这个握手过程:
- Discover(发现):客户端广播「有没有 DHCP 服务器呀?」
- Offer(提供):服务器提供一个地址 + 各种选项
- Request(请求):客户端请求接受那个提供
- Ack(确认):服务器确认(租约自此生效)
有两个重要的运维细节很容易被忽略:
- 租约会过期,也会续租。 客户端会在租约进行到一半左右(通常约 50%)时尝试续租,如果续租失败,它们可以通过向任意 DHCP 服务器广播来「重新绑定(rebind)」。
- DHCP 可以借助中继跨子网工作。 广播无法穿过路由器,所以网络中常常部署一个 DHCP 中继(relay)(通常就在路由器上),它把 DHCP 请求转发给一台集中式的服务器。
这种「有状态(stateful)」的模型对管理员来说很简单:有一个统一的地方可以审计、预留静态租约以及管理各种选项。
SLAAC(IPv6)
IPv6 引入了 SLAAC(无状态地址自动配置,Stateless Address Autoconfiguration),因为这个世界需要为数以十亿计的设备编号,而不可能靠一台中心服务器去追踪每一个分配。
在 SLAAC 环境下,路由器并不逐个发放地址。取而代之的是,它周期性地发送 路由器通告(Router Advertisements,RA)(它属于 NDP/ICMPv6 的一部分),内容大致是:
- 「这条链路的**前缀(prefix)**是这个(通常是
/64)。」 - 「默认网关是这个。」
- 「这些是相关的时间参数(valid lifetime、preferred lifetime)。」
随后,每台主机通过组合以下两部分,自己生成地址:
- 通告里的前缀
- 自己生成的接口 ID(Interface ID)(低 64 位)
出于隐私方面的考虑,这个接口 ID 并不总是从 MAC 地址推导而来。现代操作系统普遍使用临时的、随机化的地址;它会随时间轮换,以降低被追踪的风险。在主机开始使用某个地址之前,它会运行 重复地址检测(Duplicate Address Detection,DAD),确保链路上没有其他人已经在用这个地址。
所以 SLAAC 的「无状态」是指:没有任何服务器维护一份记录主机地址的租约数据库。网络只负责通告前缀,主机自己挑选地址。(在实践中,把 SLAAC 和 DHCPv6 混用也很常见:用 SLAAC 来获得地址,用 DHCPv6 来获取 DNS / 搜索域,具体取决于网络策略。)
DHCPv6 前缀委派(PD)
下面这块拼图,正是让家庭 IPv6 与家庭 IPv4 体验大不相同的关键所在:在 IPv4 时代,家庭网络常常依赖 NAT——你的路由器只拿到一个公网 IP,然后把其他所有设备都藏在它后面。而在 IPv6 中,NAT 是不被鼓励的;虽然你确实可以在 OpenWRT 之类的路由器上配置 NAT66,但这并不是常规做法(我是说,IPv6 地址多得是,何必折腾呢?)。
IPv6 的目标是恢复端到端寻址,所以你家的路由器需要的不只是一个地址,而是一整个地址块,大到足以切分成多个 /64 的局域网(访客 Wi-Fi、IoT VLAN 等等)。这正是 PD 的用武之地。
可以把它理解成一个两级的过程:
- ISP -> 路由器(DHCPv6-PD): 你的路由器通过一个 **IA_PD(Identity Association for Prefix Delegation,前缀委派的身份关联)**来请求一个前缀。ISP 会「委派」给你的路由器一个诸如
/56或/60的块。 - 路由器 -> 局域网主机(通过 RA 进行 SLAAC): 你的路由器拿到那个被委派的块后,为每个局域网段各选出一个
/64,并通过 **路由器通告(RA)**逐一通告这些/64。主机随后用 SLAAC 自行分配地址。
路由
那么,一个数据包究竟是怎样横跨大洋、找到去路的呢?路由器依据一种叫做**最长前缀匹配(Longest Prefix Match,LPM)**的逻辑来做决策。路由器并不会去记住地球上的每一个 IP 地址,相反,它记住的是「前缀」(回想我们上面讨论的 CIDR)。如果一个数据包同时匹配路由表里的多个条目,路由器总会挑选最具体的那一个(比如,若 /24 和 /22 都匹配,它会选择 /24 的路由)。
但这些表又是从哪儿来的呢?这就是路由协议的领域了。根据作用范围的不同,它们被分成两个截然不同的家族:IGP 和 BGP。
IGP
内部网关协议(Interior Gateway Protocols,IGP)工作在单个 AS(自治系统,Autonomous System)内部。
什么是自治系统?
请记住:我们把整个互联网看成一个「网络的网络」。它不是一个中心化的系统,而更像一个联邦式的系统。在每一个小网络内部,我们可以有自己的路由策略。为了管理这种复杂性,人们引入了自治系统(AS)这一概念。
自治系统(AS)是由单一组织控制、并对外呈现统一路由策略的一组 IP 网络与路由器的集合。每个 AS 都会被分配一个唯一的 AS 编号(ASN)以作标识。
主要有两大类 IGP 协议:
- 距离矢量协议(Distance-Vector Protocols)
- 链路状态协议(Link-State Protocols)
你很可能完全不知道上面这两种协议在讲什么,这很正常。但在深入展开之前,先让我给你一个快速的总结:
- 距离矢量协议是通过周期性地获取邻居的路由表,来得到对整个网络的全局视图。
- 链路状态协议是通过本地计算、并向全网洪泛(flooding)链路状态通告,来得到对整个网络的全局视图。
也许上面的解释很糟糕 😢,也许你还是没抓住要点。别担心,希望你能从下面的细节里把它弄明白。
距离矢量协议
我们先看一张图,来理解距离矢量协议是怎么工作的:
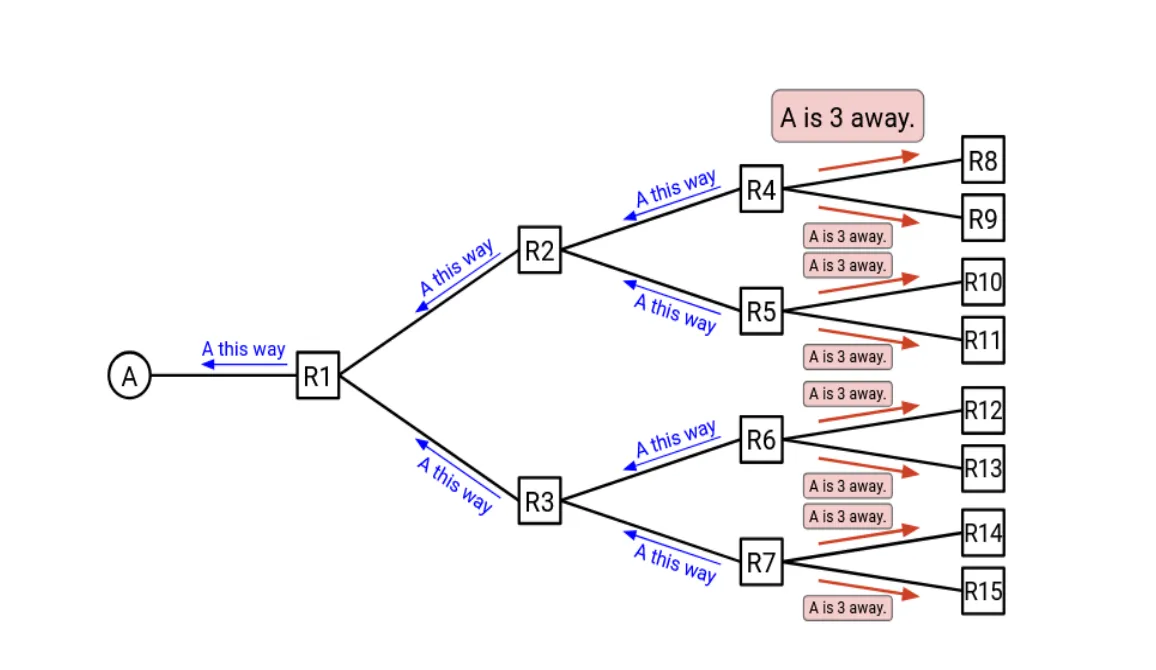
在距离矢量协议中,每台路由器维护一张表(即「矢量」),其中列出了到每个目的地的已知最优距离,以及到达该目的地的下一跳(next hop)。每隔一段时间,每台路由器就把自己的表分享给它的直接邻居。形式化地,我们可以这样描述更新过程:
- 当你听说有一条通往某个目的地的路径时,在以下情况下更新你的表:
- 你还没有任何到达该目的地的路径,或者
- 这条新路径比你当前已知的路径更短。
- 把更新后的表告诉你的邻居。
这个过程正是我们上面说的「周期性地获取邻居的路由表」。路由器通过「邻居给出的结果」+「到达该邻居的开销」来得到到每个目的地有多远。
但你或许已经注意到,这个过程存在一些问题。最主要的问题是:如果一条链路断了,可能要过很久所有路由器才会意识到这条路径已经失效,并找到新的最优路径。
针对上述问题,一个简单的优化是加入毒化报文(poison packets)机制。当一台路由器检测到某条链路断开时,它会立即告知邻居:到受影响目的地的距离是无穷大(或某个非常大的数)。但加入这种报文也会引入一些我们此前没遇到过的问题(这里我不打算展开)。如果你想看看加入毒化报文之后的最终算法,它在这里:
- 当你听到关于某个目的地的一条通告时,在以下情况下更新表并重置计时器:
- 该目的地不在表中,或者
- 通告里的开销 + 链路开销优于已知的最优开销,或者
- 该通告来自当前的下一跳(包括毒化通告)。
- 当表发生变化时,向邻居通告更新;并周期性地通告。
- 不要把更新通告回给下一跳(水平分割,split horizon),或者把毒化信息通告回去(毒性逆转,poison reverse)。
- 任何 ≥ 某个阈值(例如 RIP 中的 16)的开销都被视为无穷大。
- 如果某条表项过期了,把它标记为毒化并通告出去。
链路状态协议
距离矢量传播的是结果(「这是我到各处的最优距离」)。链路状态传播的是事实(「这是我直接相连的对象」)。看下面这张图:
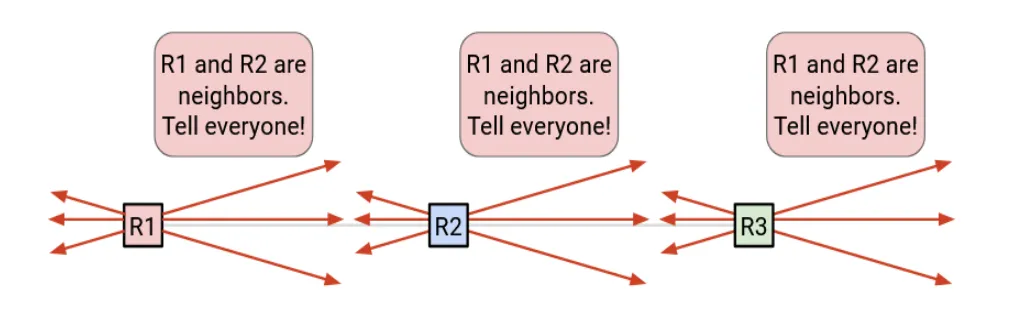
在链路状态协议(OSPF / IS-IS)中,每台路由器做三件大事:
-
发现邻居
路由器之间交换 hello 报文,以找到相邻的路由器并建立邻居关系。 -
洪泛链路状态通告
每台路由器通告它本地链路的状态与开销(例如「我有一条到 R2 的链路,开销为 10」)。
这些 LSA 会被洪泛(不断向外转发),直到收敛。 -
运行 Dijkstra 算法
一旦所有路由器都拥有相同的拓扑数据库,每台路由器就独立地运行 Dijkstra 算法,计算出一棵以自身为根的最短路径树。
计算结果就成为该路由器的转发表项(「要到达前缀 X,下一跳是 Y」)。
相比距离矢量,这种方式有几个优势:
- 收敛更快: 由于路由器拥有完整的拓扑视图,链路状态协议能更快地对变化做出反应。
- 路由逻辑一致: 所有路由器计算出的是同一棵最短路径树,因而更不容易出现路由环路。
不过它也有取舍,一个主要问题是它消耗更多的 CPU / 内存: 维护一个数据库并运行 Dijkstra,比基础的距离矢量要重得多。
BGP
IGP 关心的是单个组织内部「按某种度量得出的最优路径」。BGP 关心的则是策略(policy),而且是跨组织的策略。请记住,网络是联邦式的:没有任何单一实体控制整个互联网。每个 AS 对于接受、偏好或通告哪些路由,都有自己的策略。要把数据包跨越 AS 边界传输,就必须遵守这些策略。
BGP(边界网关协议,Border Gateway Protocol)是互联网的域间路由协议。它常被描述为一种**路径矢量(path-vector)**协议:
为什么不用链路状态?
回想一下,在链路状态协议中,每台路由器都向全网洪泛链路状态通告,以构建出完整的拓扑图。从隐私的角度看,这对 BGP 来说是无法接受的。每个 AS 都想让自己的内部拓扑与客户信息保持私密。因此,BGP 只共享可达性信息(哪些前缀可以到达)以及一组路径属性,而不暴露 AS 的内部结构。
从宏观上看,全球互联网由许许多多的 AS 组成(ISP、云服务商、企业、高校等)。每个 AS 在内部可以运行自己的 IGP(OSPF / IS-IS 等)。而在边界处,各个 AS 用 BGP 来交换各自能够到达哪些前缀。
关于 peering 与 transit、iBGP 与 eBGP、热土豆路由(hot-potato routing)的更多细节,请参阅我那个关于计算机网络如何为你的数据包选路的小分享。这里我就略去这些细节了。